When compressing a file makes it bigger
August 26, 2024
Bijay Khapung
Yes you heard it correct, sometimes compressing a file makes it bigger. If you don't believe me create a text file and write any one sentence in it, now compress the file with any compression program you like. Compare the file size before and after compressing, you will notice that the file size increased after compressing. In this blog, I'm going to explain why that happened and also about a relatively simple compression algorithm that is still used widely today.
Compression is the process of reducing size of data. The data may be of any type image, text, audio, video. There are two types of compression algorithms, one is lossless and another is lossy. In the simplest term, if some of the original data is lost during compression then it is a lossy algorithm and vice versa. In this blog, I'm about to talk about a lossless algorithm called Huffman coding and how I used it to create a program to compress text files. Huffman is still used for compressing images and texts today.
Huffman coding is a very simple compression algorithm. Computers represent text in UTF-8, they use 16 bits to represent one character it would be wonderful if we could reduce 16 bits to less bits to represent one character. That's exactly the main idea behind Huffman coding, to represent the most frequently occuring character with the least number of bits. Let's walkthrough how it works
First let's count the frequency of each character and store it in a hashmap
/* Hashmap to store frequency of characters*/
HashMap *freq_map = initialize_hashmap(200, FREQ_TYPE);
BucketData *data = NULL;
/* Read each character one by one from file and update frequency of each character */
while ((c = fgetc(fp)) != EOF) {
char *ch = malloc(sizeof(char) * 2);
ch[0] = c;
ch[1] = '\0';
if ((data = get_hashmap(freq_map, ch)) != NULL) {
data->freq = data->freq + 1;
} else {
BucketData *f = malloc(sizeof(BucketData));
f->freq = 1;
insert_hashmap(freq_map, ch, f);
}
total_char++;
}
Above is from the compressing program I wrote. It reads character one by one from a file and stores count of each character's frequency in a custom created hash map.
Now we need to insert the character and its frequency count in a min priority queue. Each node should store a character, frequency, its left and right child.
/* Create min priority queue */
/* This will be used when creating the huffman tree */
PQueue *q = initialize_pqueue(200);
for (int i=0; i<freq_map->size; i++) {
if (freq_map->buckets[i] != NULL) {
Node *tmp = malloc(sizeof(Node));
tmp->ch = freq_map->buckets[i]->key[0];
tmp->freq = freq_map->buckets[i]->data->freq;
tmp->left = NULL;
tmp->right= NULL;
enqueue_pqueue(q, tmp);
}
}
Now the magic begins to happen, let's pop two nodes from the min priority queue and create a single node by combining them until only one node is left in the queue. The end result is a Huffman tree.
/* Create a huffman tree from a given priority queue. Returns the root node of the tree */
Node *create_htree(PQueue *q) {
while (get_size_pqueue(q) > 1)
{
Node *left_node = dequeue_pqueue(q);
Node *right_node = dequeue_pqueue(q);
Node *new_node = malloc(sizeof(Node));
new_node->ch = 0;
new_node->freq = left_node->freq + right_node->freq;
new_node->left = left_node;
new_node->right = right_node;
enqueue_pqueue(q, new_node);
}
return q->queue[0];
}
When we combine, we take the sum of left node and right node's frequency and use the result as the frequency of the new node created.
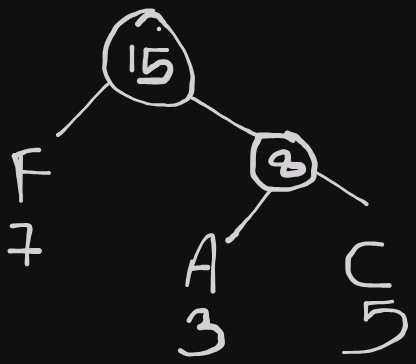
Above is a huffman tree from three characters. Notice that only leaf nodes contain characters. Now we need to traverse the tree from the top to generate a binary encoding for each character. When we traverse left, count that as a '0' and when we traverse right count that as a '1'.
The binary encoding of each character in the above image would be F - 0, A - 10 and C - 11. Notice that 'F' was the character with the highest frequency so it has the shortest binary encoding. We don't need to use 16 bits to represent 'F' now, we can represent it using '0' only.
The theoretical work is done. You must have the idea of how to compress and decompress texts using a given binary encoding from a Huffman tree.
Still we have one hard obstacle to solve. It's really easy to compress a file given the binary encodings. But how to decompress the compressed files. We would need to store the encodings inside the compressed file. This is exactly why when you compress very small files the file sizes get bigger as they need to store metadata on how to decompress the file back.
I would have to store the encodings in binary format and I didn't see a way on how to store the original Huffman tree, as it contained pointers. So, I created a array of structs that stored a character and its mapping. Then I wrote the array in the head of the compressed file in binary format.
FILE *new_fp = fopen("compressed.bj", "wb");
fwrite(&total_char, sizeof(uint64_t), 1, new_fp);
/* Write the codes->alphabet hashmap metadata first */
MetaData meta[alph_map->filled];
int counter = 0;
for (int i=0; i<alph_map->size; i++) {
if (alph_map->buckets[i] != NULL) {
strcpy(meta[counter].code, alph_map->buckets[i]->key);
meta[counter].alphabet = alph_map->buckets[i]->data->string[0];
counter++;
if (counter == alph_map->filled) break; /* Don't remove dangerous things happen */
}
}
int meta_size = alph_map->filled; /* Starting from index 1 */
fputc(meta_size, new_fp); /* Write the metadata array size */
fwrite(meta, sizeof(MetaData), meta_size, new_fp);
Reading each character from the file and writing the compressed binary encoding for the character involved a lot of bit manipulations. I created a buffer to store 16 chars, reading each bit character into the buffer then when the buffer got full I created a `uint16_t` then used bit manipulations to convert the 16 chars into 16 actual bits.
uint16_t two_byte = 0;
for (int i=0; i <= buf_index; i++) {
two_byte |= buf[i] == '0' ? 0 << (15 - i) : 1 << (15 - i);
}
fwrite(&two_byte, sizeof(uint16_t), 1, new_fp);
I used a similar technique to decompress the file. I read two bytes at once, then I read each bit one by one from the variable and stored the bits in a char buffer. I queried the hashmap on each time bit was read. If a character was found, I wrote the character in the file and reset the char buffer.
I'm going to end the blog here as going into each and every detail would result in a very long blog. If you are interested in learning more, please check my github code on this and see this awesome visualization.